接續昨天的部份,我們繼續。(從Now that we have this process ...開始)
在講程式之前,我們先來看一下這段程式的目的
我們需要替換嵌入,那為什麼呢?
模型的嵌入是它對token的語義理解的表示。如果我們更改嵌入,模型的解釋和輸出可能會有所不同。在這一步中,我們將替換句子中的一個token的嵌入,並且觀察這對模型輸出的影響
所以我們主要會做2件事:
準備好了就開始看code 吧!
Tokenization:
首先我們將提示句子轉化為tokens。
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
input_ids = text_input.input_ids.to(torch_device)
獲取原始Token Embeddings:
使用模型,我們可以獲得每個token的嵌入。
token_embeddings = token_emb_layer(input_ids)
選擇新的嵌入:
現在我們選擇一個新的嵌入來替換原始嵌入。選擇了token 2368的嵌入作為替換。
replacement_token_embedding = text_encoder.get_input_embeddings()(torch.tensor(2368, device=torch_device))
替換嵌入:
找到要替換的token位置,並將其嵌入替換為新的嵌入。
token_embeddings[0, torch.where(input_ids[0]==6829)] = replacement_token_embedding.to(torch_device)
組合嵌入:
將token嵌入與位置嵌入組合,形成模型的完整輸入。
input_embeddings = token_embeddings + position_embeddings
獲取輸出嵌入:
最後我們組合後的嵌入輸入模型,就可以獲得輸出嵌入。
modified_output_embeddings = get_output_embeds(input_embeddings)
好,大功告成!讓我們觀察看看這些嵌入的具體值
print(modified_output_embeddings.shape)
modified_output_embeddings
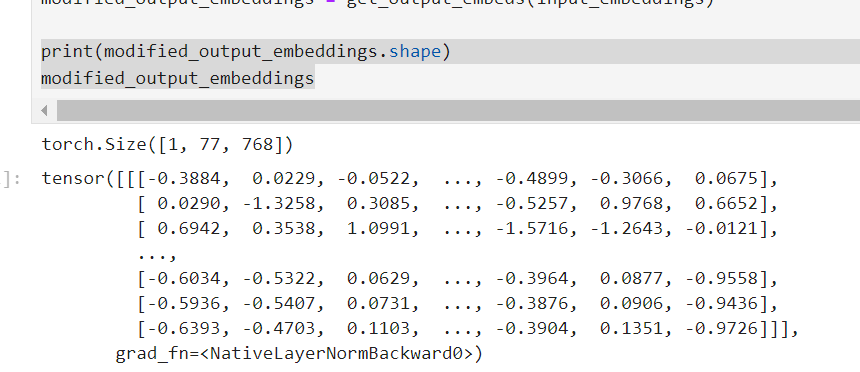
講師說我們可以觀察,前幾個嵌入與原始的相同,但後面的嵌入不同。也就是說只要我們替換了原始句子中的一個token的嵌入,之後的所有輸出嵌入都會受到影響。
接下來我們來使用這些嵌入表示來生成圖像,我們會生成生成了一個無條件的嵌入,並與文本嵌入組合,
根據模型的輸出多次更新隱藏狀態,最後將隱藏狀態轉換為圖像。
在先前的筆記中,我們已經探索了如何使用Stable Diffusion模型來生成圖像。我們主要是通過嵌入(embeddings)來指導模型生成特定的圖像。這些嵌入通常是從文本編碼器中獲得的,並用於指導Stable Diffusion模型生成具有特定語義的圖像。
但是,當我們有能力修改或操縱這些嵌入時,會發生什麼情況呢?這正是這段程式碼的目的。我們不僅希望看到原始的嵌入如何影響生成的圖像,而且還想看到當我們修改這些嵌入時會發生什麼。
這段程式碼的主要目的是:使用一組被修改過的嵌入,並觀察它如何影響生成的圖像。這可以幫助我們更深入地了解嵌入如何影響生成的圖像,並提供一種方式來實驗和玩耍這些嵌入,以看到不同的結果。
主要步驟如下:
現在就來看code
設定參數
height = 512
width = 512
num_inference_steps = 30
guidance_scale = 7.5
generator = torch.manual_seed(32)
batch_size = 1
製作無條件嵌入
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
這裡首先獲取文本的最大長度,然後創建一個空的嵌入(uncond_embeddings),這是一種不包含任何具體文本信息的嵌入。最後,這個無條件嵌入和提供的文本嵌入結合起來。
預備調度器和潛在向量:
set_timesteps(scheduler, num_inference_steps)
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
latents = latents * scheduler.init_noise_sigma
調度器確定去噪步驟的具體數量。潛在向量是一個隨機生成的noise,被用來生成圖像。
主生成循環:
# 5. 主循環
for i, t in tqdm(enumerate(scheduler.timesteps), total=len(scheduler.timesteps)):
latent_model_input = torch.cat([latents] * 2)
sigma = scheduler.sigmas[i]
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
# 預測噪聲殘差
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
# 執行導向
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# 計算先前的噪聲樣本 x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
return latents_to_pil(latents)[0]
這段的精髓在於允許我們使用修改過的嵌入來生成圖像,我們來看一下生成的圖。


 iThome鐵人賽
iThome鐵人賽